
Amino App Pc Download Archives

Amino App Pc Download Archives
Category Archives: Technology – Insights
Once you’ve found product/market fit, scaling a SaaS business is all about honing your go-to-market efficiency. Many extremely helpful metrics and analytics have been developed to provide instrumentation for this journey. LTV (lifetime value of a customer), CAC (customer acquisition cost), Magic Number, and SaaS Quick Ratio, are all very valuable tools. The challenge in using derived metrics such as these, however, is that there are often many assumptions, simplifications, and sampling choices that need to go into these calculations, thus leaving the door open to skewed results.
For example, when your company has only been selling for a year or two, it is extremely hard to know your true Lifetime Value of a Customer. For starters, how do you know the right length of a “lifetime”? Taking 1 divided by your annual dollar churn rate is quite imperfect, especially if all or most of your customers have not yet reached their first renewal decision. How much account expansion is reasonable to assume if you only have limited evidence? LTV is most helpful if based on gross margin, not revenue, but gross margins are often skewed initially. When there are only a few customers to service, COGS can appear artificially low because the true costs to serve have not yet been tracked as distinct cost centers as most of your team members wear multiple hats and pitch in ad hoc. Likewise, metrics derived from Sales and Marketing costs, such as CAC and Magic Number, can also require many subjective assumptions. When it’s just founders selling, how much of their time and overhead do you put into sales costs? Did you include all sales related travel, event marketing, and PR costs? I can’t tell you the number of times entrepreneurs have touted having a near zero CAC when they are just starting out and have only handfuls of customers–which were mostly sold by the founder or are “friendly” relationships. Even if you think you have nearly zero CAC today, you should expect dramatically rising sales costs once professional sellers, marketers, managers, and programs are put in place as you scale.
One alternative to using derived metrics is to examine raw data, less prone to assumptions and subjectivity. The problem is how to do this efficiently and without losing the forest for the trees. The best tool I have encountered for measuring sales efficiency is called the 4×2 (that’s “four by two”) which I credit to Steve Walske, one of the master strategists of software sales, and the former CEO of PTC, a company renowned for their sales effectiveness and sales culture. [Here’s a podcast I did with Steve on How to Build a Sales Team.]
The 4×2 is a color coded chart where each row is an individual seller on your team and the columns are their quarterly performance shown as dollars sold. [See a 4×2 chart example below]. Sales are usually measured as net new ARR, which includes new accounts and existing account expansions net of contraction, but you can also use new TCV (total contract value), depending on which number your team most focuses. In addition to sales dollars, the percentage of quarterly quota attainment is shown. The name 4×2 comes from the time frame shown: trailing four quarters, the current quarter, and next quarter. Color coding the cells turns this tool from a dense table of numbers into a powerful data visualization. Thresholds for the heatmap can be determined according to your own needs and culture. For example, green can be 80% of quota attainment or above, yellow can be 60% to 79% of quota, and red can be anything below 60%. Examining individual seller performance in every board meeting or deck is a terrific way to quickly answer many important questions, especially early on as you try to figure out your true position on the Sales Learning Curve. Publishing such “leaderboards” for your Board to see also tends to motivate your sales people, who are usually highly competitive and appreciate public recognition for a job well done, and likewise loathe to fall short of their targets in a public setting.
Sample 4×2 Chart
Some questions the 4×2 can answer:
Overall Performance and Quota Targets: How are you doing against your sales plan? Lots of red is obviously bad, while lots of green is good. But all green may mean that quotas are being set too low. Raising quotas even by a small increment for each seller quickly compounds to yield big difference as you scale, so having evidence to help you adjust your targets can be powerful. A reasonable assumption would be annual quota for a given rep set at 4 to 5 times their on-target earnings potential.
Trendlines and Seasonality: What has been the performance trendline? Are results generally improving? Was the quarter that you badly missed an isolated instance or an ominous trend? Is there seasonality in your business that you have not properly accounted for in planning? Are a few elephant sized deals creating a roller-coaster of hitting then missing your quarterly targets?
Hiring and Promoting Sales Reps: What is the true ramp time for a new rep? You’ll see in the sample 4×2 chart that it is advised to show start dates for each rep and indicate any initial quarter(s) where they are not expected to produce at full capacity. But should their first productive quarter be their second quarter or third? Should their goal for the first productive quarter(s) be 25% of fully ramped quota or 50%? Which reps are the best role models for the others? What productivity will you need to backfill if you promote your star seller into a managerial role?
Evaluating Sales Reps: Are you hitting your numbers because a few reps are crushing it but most are missing their numbers significantly? Early on, one rep coming in at 400% can cover a lot of sins for the rest of the team. Has one of your productive sellers fallen off the wagon or does it look like they just had a bad quarter and expect to recover soon? Is that rep you hired 9 months ago not working out or just coming up to speed?
Teams and Geographies: It is generally useful to add a column indicating the region for each rep’s territory and/or their manager. Are certain regions more consistent than others? Are there managers that are better at onboarding their new sellers than others?
Capacity Planning: Having a tool that shows you actual rep productivity and ramp times gives you the evidence-based information you need to do proper capacity planning. For example, if you hope to double sales next year from $5M ARR to $10MM, how many reps do you need to add–and when–based on time to hire, time to ramp, and the percentage of reps likely to hit their targets? Too few companies do detailed bottoms up planning at this level of granularity, and as a result fail to hit their sales plans because they simply have too few productive reps in place early enough.
There are many other questions the 4×2 can shed light on. I find it especially helpful during product/market fit phase and initial scaling. We tend to spend a few minutes every board meeting on this chart, with the VP Sales providing voice over, but not reciting every line item. As your team gets larger and the 4×2 no longer fits on one slide, it might be time to place the 4×2 in the appendix of your Board deck for reference.
One question often asked about implementing the 4×2 is what numbers to use for the current and next quarter forecasts? If your sales cycles are long, such as 6 months, then weighted pipeline or “commits” are good proxies for your forward forecasts. In GTM models with very short cycles, it will require more subjective judgement to forecast a quarter forward, so I recommend adding a symbol such as ↑,  , or ↓ indicating whether the current and forward quarter forecast is higher, lower, or the same as the last time you updated the 4×2. Over time you’ll begin to see whether your initial forecasts tend to bias too aggressively or too conservatively, which is a useful thing to discover and incorporate into future planning.
, or ↓ indicating whether the current and forward quarter forecast is higher, lower, or the same as the last time you updated the 4×2. Over time you’ll begin to see whether your initial forecasts tend to bias too aggressively or too conservatively, which is a useful thing to discover and incorporate into future planning.
There are lots of ways to tweak this tool to make it more useful to you and your team. But what I like most about it is that unlike many derived SaaS metrics, the 4×2 is based on very simple numbers and thus “the figures don’t lie.”
To Measure Sales Efficiency, SaaS Startups Should Use the 4×2 was originally published on TechCrunch‘s Extra Crunch.
Source: https://techcrunch.com/extracrunch/
Four years ago I met a recent Stanford grad named Isaac Madan. He had an impressive computer science background, had founded a startup in college, and was interested in venture capital. Though we usually look to hire folks with a bit more experience under their belt, Isaac was exceptionally bright and had strong references from people we trusted. Isaac joined Venrock and for the next two years immersed himself in all corners of technology, mostly gravitating towards enterprise software companies that were utilizing Artificial Intelligence and Machine Learning. Isaac packed his schedule morning, noon, and night meeting with entrepreneurs, developing a deep understanding of technologies, go-to-market strategies, and what makes great teams tick. Isaac was a careful listener, and when he spoke, his comments were always insightful, unique, and precise. Within a year, he sounded like he had been operating in enterprise software for over a decade.
After two years in venture, Isaac got the itch to found another startup. He paired up with a childhood friend, Rohan Sathe, who had been working at Uber. Rohan was the founding engineer of UberEats, which as we all know, grew exceptionally fast, and today generates over $8Bn in revenue. Rohan was responsible for the back-end systems, and saw firsthand how data was sprayed across hundreds of SaaS and data infrastructure systems. Rohan had observed that the combination of massive scale and rapid business change created significant challenges in managing and protecting sensitive data. As soon as they teamed up, Isaac and Rohan went on a “listening tour,” meeting with enterprise IT buyers asking about their business priorities and unsolved problems to see if Rohan’s observations held true in other enterprises. Isaac and I checked in regularly, and he proved to be an extraordinary networker, leveraging his contacts, his resume, and the tenacity to cold call, conducting well over 100 discovery interviews. Through these sessions, it was clear that Isaac and Rohan were onto something. They quietly raised a seed round last year from Pear, Bain Capital Ventures, and Venrock, and started building.
One of the broad themes that Isaac and I worked on together while at Venrock was looking for ways in which AI & ML could re-invent existing categories of software and/or solve previously unresolvable problems. Nightfall AI does both.
On the one hand, Nightfall (formerly known as Watchtower) is the next generation of DLP (Data Loss Prevention), which helps enterprises to detect and prevent data breaches, such as from insider threats–either intentional or inadvertent. DLPs can stop data exfiltration and help identify sensitive data that shows up in systems it should not. Vontu was one of the pioneers of this category, and happened to be a Venrock investment in 2002. The company was ultimately acquired by Symantec in 2007 at the time that our Nightfall co-investor from Bain, Enrique Salem, was the CEO of Symantec. The DLP category became must-have and enjoyed strong market adoption, but deploying first-generation DLP required extensive configuration and tuning of rules to determine what sensitive data to look for and what to do with it. Changes to DLP rules required much effort and constant maintenance, and false positives created significant operational overhead.
Enter Nightfall AI. Using advanced machine learning, Nightfall can automatically classify dozens of different types of sensitive data, such as Personally Identifiable Information (PII), without static rules or definitions. Nightfall’s false positive rate is exceptionally low, and their catch rate extremely high. The other thing about legacy DLPs is that they were conceived at a time when the vast majority of enterprise data was still in on-premise systems. Today, however, the SaaS revolution has meant that most modern businesses have a high percentage of their data on cloud platforms. Add to this the fact that the number of business applications and end-users has grown exponentially, and you have an environment where sensitive data shows up in a myriad of cloud environments, some of them expected, like your CRM, and some of them unexpected and inadvertent, like PII or patient health data showing up in Slack, log files, or long forgotten APIs. This is the unsolved problem that drew Isaac and Rohan to start Nightfall.
More than just a next-gen DLP, Nightfall is building the control plane for cloud data. By automatically discovering, classifying, and protecting sensitive data across cloud apps and data infrastructure, Nightfall not only secures data, but helps ensure regulatory compliance, data governance, safer cloud sharing and collaboration, and more. We believe the team’s impressive early traction, paired with their clarity of vision, will not only upend a stale legacy category in security but also usher in an entirely new way of thinking about data security and management in the cloud.This open ended opportunity is what really hooked Venrock on Nightfall.
Over the past year, Nightfall has scaled rapidly to a broad set of customers, ranging from hyper-growth tech startups to multiple Fortune 100 enterprises, across consumer-facing and highly-regulated industries like healthcare, insurance, and education. In our calls with customers we consistently heard that Nightfall’s product is super fast and easy to deploy, highly accurate, and uniquely easy to manage. Venrock is pleased to be co-leading Nightfall’s Series A with Bain and our friends at Pear. After 21 years in venture, the thing that I still enjoy most is working closely with entrepreneurs to solve hard problems. It is all the more meaningful when I can work with a high potential young founder, from essentially the beginning of their career, and see them develop into an experienced entrepreneur and leader. I am thrilled to be working with Isaac for a second time, and grateful to be part of Nightfall’s journey.
Source: http://vcwaves.wordpress.com

Over the last seven years, a bunch of variables – some influenced by our effort and attention, while others definitely out of our control – fell into place much more positively than usual. The result being that Cloudflare and 10X Genomics – companies in which Venrock led Series A financings – both went public this week. These are terrific, emergent businesses creating material, differentiated value in their ecosystems… with many more miles to go. Their founder leaders – Ben Hindson and Serge Saxonov at 10X, Michelle Zatlyn and Matthew Prince at Cloudflare – are inspiring learners with extreme focus on driving themselves and their organizations to durably critical positions in their industries. They, and their teams, deserve kudos for their accomplishments thus far, especially given they are sure to remain more focused on the “miles to go” than the kudos.
The VC humble brag is a particularly unattractive motif, so let’s be clear, these returns for Venrock will be great. Our initial investments, while probably at appropriate risk adjusted prices then, now look exceedingly cheap. In addition, each company had operational success in a forgiving capital environment, so our ownership positions were not overly diluted. Whenever we do crystallize these positions, each will return substantially more than the fund’s committed capital. In addition, we hope that Cloudflare and 10X’s success will help us connect, and partner, with one or two additional tenaciously driven company builders.
But none of this is the reason for actually putting pen to paper today. The important nugget, too often buried amidst companies’ successes, is reflected in the opening sentence of this piece. Each of these businesses are mid-journey on the path of 10,000 steps on a knife edge.
To the pundits and prognosticators, startups begin with a person and an idea (maybe a garage) that leads to a breakthrough, after which money falls out of the air. This narrative ignores the ongoing barrage of strategic and executional hurdles, and also the asymmetry of consequences. One wrong move or bad break can erase the gains resulting from many right calls – this is life on the knife edge. This phenomenon of disproportionately large negative repercussions has corollaries in the realm of integrity and respect – it is difficult to gain, but easy to lose. One step off the knife edge is a problem.
Successful start-ups are the result of teams making thousands of – much more often than not – good choices, but as importantly, rapidly fixing the bad choices. This is hard, lonely, and unforgiving work that isn’t for most people, especially at the formative stage. These pioneers invest themselves completely to forever change their industries.
So while – for the first time – two Venrock portfolio companies are ringing the bell at different stock exchanges on the same day, knowing these teams, I am certain that they will quickly return to their journey of asymmetric risk/reward because it is their nature. These IPO’s are one step along that knife edge, in this case to gather capital, provide liquidity and allow for maturation of the shareholder base. Congratulations to the employees of Cloudflare and 10x during this moment of success – thank you.

I first met Brian O’Kelley in the summer of 2008, when he was looking to raise his first institutional round of funding for AppNexus. Brian had a vision for how the online advertising market was going to evolve and believed that building highly scaled services for both sides of the industry – publishers that want to sell ads and marketers who want to buy them – would enable a more efficient and cost-effective marketplace. Software, data, and machine learning ultimately enabled ad transactions to occur programmatically and in real time on the AppNexus platform.
We at Venrock believed in Brian’s vision, but that was not the main reason we invested. We look first and foremost for special entrepreneurs, like former Venrock entrepreneurs Gordon Moore at Intel, Steve Jobs at Apple, Gil Shwed at Check Point, Steve Papa at Endeca, and more recently Michael Dubin at Dollar Shave Club. We call these folks “Forces of Nature”.
While Venrock does not have a formal or complete definition of “Force of Nature”, they do all share the following characteristics: they are scary intelligent, have far reaching vision for a market, think very big, and are EXTREMELY competitive.
Brian had all of these characteristics in spades!
I prepared an early investment description for my partners at Venrock called an NDFM (New Deal First Mention). This memo is designed to briefly describe the business for the broader partnership team to contemplate while an investing partner begins the diligence process.

Click here to read our original investment memo!
I was very interested in the business opportunity, as Venrock had invested in plenty of adtech businesses including DoubleClick many years before, but I was mostly excited about working with Brian. I really believed he was a “Force of Nature”.
One thing about “Forces of Nature” is that they stand out and pretty much everyone who knows them has an opinion on them. The opinions on Brian were consistent that he is a visionary and very smart, but were all over the map in terms of his ability to build and lead a company. The more time I spent with him, the more he grew on me, and I believed he had what it takes.
We then led the first institutional round at AppNexus investing $5.7MM for more than 20% ownership. When our investment was announced, I had two other VCs from other firms reach out to me and say I made a mistake backing Brian. This had never happened to me before, but in some ways I liked hearing it because non-consensus deals tend to have more upside (and downside) than straight down the middle deals. When I shared this feedback (but not the names) with Brian, his reaction was predictable for a “Force of Nature” … he laughed, said they are idiots and we are going to build a killer company to prove it.
While sitting on the AppNexus board, I challenged Brian that I would ultimately measure his performance not on the outcome of the company, but on the quality of the team he recruits, develops, and leads.
Well, Brian has clearly graded out as an A+ CEO as he has built an absolutely, positively world-class management team in NYC. They helped AppNexus fulfill Brian’s original vision by enabling hundreds of publishers and thousands of marketers to serve billions of ads, which led to the acquisition of the company and about 1,000 AppNexians by AT&T, announced earlier today.
I would like to thank Brian and that fantastic, all world, all universe team including Michael Rubenstein, Jon Hsu, Ryan Christensen, Ben John, Catherine Williams, Tim Smith, Nithya Das, Pat McCarthy, Kris Heinrichs, Josh Zeitz, Craig Miller, Tom Shields, Julie Kapsch, Dave Osborn, Doina Harris and many others for allowing Venrock the opportunity to be part of a very exciting journey and a terrific outcome.
And we now look forward to meeting that next “Force of Nature”!
Venrock has a 40-year history of investing across technology and healthcare, including more than a decade at the intersection of those two sectors. Earlier this month we expanded our technology investing team with the addition of Tom Willerer. Continuing to increase the depth and breadth of Venrock’s value-add to entrepreneurs, we are honored that DJ Patil is joining Venrock as an Advisor to the Firm.
According to DJ, “Venrock has a long and incredible history of helping entrepreneurs create new categories – Apple; Cloudflare; Dollar Shave Club; Gilead; Illumina; Nest; Athenahealth. Given their experience across healthcare and technology, they are well-situated to help build an entirely new generation of data science/AI, healthcare, security, as well as consumer and enterprise internet companies. I have known this team for years and am eager to help their effort going forward.”
Best known for coining the term “data science”, DJ helped establish LinkedIn as a data-driven organization while serving as the head of data products, Chief Scientist and Chief Security Officer from 2008 – 2011. DJ spent the last several years as the Chief Data Scientist of the United States, working in the White House under President Obama. The first person to hold this role, DJ helped launch the White House’s Police Data Initiative, Data-Driven Justice, and co-led the Precision Medicine Initiative. Immediately prior to the White House, he led the product team at RelateIQ prior to its acquisition by Salesforce.
DJ will be working with the Venrock investing team and advising Venrock portfolio companies on healthcare, security, data and consumer internet challenges and opportunities. His decades working in the tech industry, combined with his expertise in government, will be a great asset to the Venrock ecosystem.

While it’s tempting to dismiss virtual goods as a niche product category limited to online role-playing games or emoji “stickers,” the impact of this market is actually much bigger than you might think. Dating back to the earliest social networks, virtual goods have played a critical role in shaping the behaviors and business models behind major trends in online engagement. Here are five ways developers and entrepreneurs can directly benefit from those learnings.
Lesson #1: Maintain Flexibility In Your Business Model
Like many online publishers, some of the earliest social game developers focused on monetization opportunities via digital advertising. Launched in 2001, one of the first to gain traction with this approach was a massive multiplayer online (MMO) role-playing game called Runescape.
The game was set in a medieval fantasy world, and featured an inventory of hundreds of virtual items which players could use to level-up their characters — attainable by completing missions or bartering with each other.
Even in the earliest days, some of the most active players expressed a willingness to pay for these items in order to enhance their experience. In fact, three surveys conducted between 2005 and 2009 suggested that at least one in five MMO players already traded game goods for real money.
Unfortunately, a sizeable portion of this trading was taking place in “black markets.”
The developers behind Runescape had certainly taken note of the behavior, but chose to clamp down on it in order to preserve the “sanctity” of their game. The official policy was to actively prohibit the buying of gold, items, or any other products linked with the game, for real world cash.
As a result, players found ways to build their own secondary markets — effectively achieving a hacked-together style of freemium economics.
Today’s modern startups have learned that ignoring the behaviors of their most engaged customers comes at a great risk. While Runescape earned its developer a respectable $30M in advertising revenue in 2008, that figure paled in comparison to an overall virtual goods market that was already valued at over a billion dollars annually (based primarily on the gaming market).
Quite a missed opportunity for a game that Guinness World Records crowned the “World’s Most Popular Free MMORPG” (2008) that same year!
Lesson #2: Fringe Behaviors Can Open Up New Markets
Runescape may have been one of the first major MMOs to fuel a “black market,” but it certainly wasn’t the last. With the rise of games like World of Warcraft, the unofficial market for virtual goods transactions grew considerably.
Among the most notable outgrowths of this trend was the practice of gold farming, whereby some players focused their time solely on accumulating in-game currency for resale. In effect, these players approached the game as their primary employment, with a relatively predictable minimum wage.
To get a sense of scale, it was estimated that the gold farming market was already worth nearly two billion non-virtual dollars globally by 2009. One article in the New York Times from 2007 estimated that 100,000 people were employed in this practice in China, with worker salaries ranging from $40 to $200 per month.
Often these operations were run as small businesses, with “bosses” earning a profit of nearly 200% on top of worker costs. In fact, this practice became so lucrative that at one point prison inmates in China were forced to play World of Warcraft in lieu of manual labor.
In addition to gold farmers, the demand for illicit virtual goods also gave rise to third-party platforms focused solely on facilitating exchanges between players. In a testament to how mainstream this market was as far back as a decade ago, a significant portion of this industry initially migrated to eBay.
However, citing a violation of its terms of service, the auction site began cracking down on virtual goods sales in 2007. This move pushed virtual goods transactions towards less transparent destinations such as Internet Gaming Entertainment (IGE).
Today there are hundreds of platforms offering “secure” opportunities to buy and sell everything from in-game currency to entire player accounts. We’re even witnessing the emergence of these transactions for casual mobile games. Days after the launch of Pokemon Go, there were already a bevy of leveled-up accounts for sale across dozens of sites. Although sales of mobile game accounts are still a small component of the secondary market, they will likely take on far more significance in years to come.
Lesson #3: Adapt To New Platforms
Over the past several years, it has become clear that smartphone screens have become the most important battleground for consumer attention. As of 2014, the number of mobile users officially surpassed the number of desktop users, and the gap continues to widen.
Mobile gaming has become a strong beneficiary of this trend. Not only have mobile games already surpassed console games in terms of total revenue, but they’re also growing at nearly five times the rate.
In fact, mobile gaming currently represent a staggering 85% of all app revenues, in any form.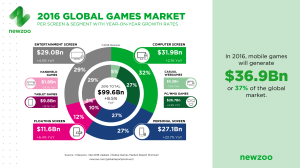
According to a recent study by Slice Intelligence, the average paying player on mobile spends $86.50 per year on in-app (virtual goods) purchases. Some games far exceed that, with Game of War: Fire Age bringing in a whopping $549.69 per paying user, and over $2M in total revenue per day at its peak.
With those kinds of economics, it’s no wonder the game’s developer, Machine Zone, could afford to drop $40M on an ad campaign featuring Kate Upton.
The rapid acceleration of this market is evidence that the appeal of virtual goods has successfully made the jump from desktop experiences to the casual smartphone market. In fact, it’s no coincidence that the same freemium model of gameplay demanded by early MMO players has emerged as the dominant framework among mobile games.
By tweaking the same model for games with shorter duration, developers successfully leveraged virtual goods in opening up an entirely new base of casual users.
Lesson #4: Engage Your Community of Makers
While developers dictate the structure of a game, users dictate its culture. Following the patterns of social engagement across the web, there is often a small subset of highly engaged players who create the customs, quirks and content that imbue a game with its lasting appeal and sense of community.
When given the tools to make things and earn recognition, this subset of users can unlock creative new experiences for all players.
One great example of this trend comes from the world of Second Life, which grew to over 1M monthly active users since its launch in 2003. Much like earlier social networks and immersive worlds, it was free to create an avatar on the platform and engage with other users. The twist came in the form of the company’s revenue model.
Second Life charged users for the purchase and rental of virtual real estate, on which landowners could build businesses (such as nightclubs and fashion outlets) and potentially earn a profit from other players. In addition, users were given the opportunity to create and sell unique virtual goods to each other.

Empowering the creativity and entrepreneurial spirit of the platform’s makers gave rise to a massive market for virtual goods. In 2009, the total size of the Second Life economy reached $567M, and by the platform’s 10 year anniversary, Linden Labs estimated that approximately $3.2 billion dollars (USD) worth of transactions had taken place. A handful of top users were reportedly cashing out over $1M in earnings per year from virtual businesses in real estate, fashion, and events management.
More recently, Valve has benefited from this phenomenon within its Steam platform for PC gaming. As of January 2015, the company announced cumulative payouts of $57 million to community members that had made in-game items, with average earnings of $38,000 per contributor. As an additional signal of market potential, Steam even announced it would facilitate the sale of virtual items for third-party games outside of its ecosystem.
Both examples demonstrate that by allowing a subset of creative users to take greater control of product experience, developers can exponentially increased both the scope of their products and community engagement.
Lesson #5: Social Capital Is An Effective Motivator
Following on the success of Second Life, Minecraft rode a similar wave into mainstream popularity after its launch in 2009. Often referred to as a “sandbox game,” Minecraft is a virtual environment where users can create their own maps and experiences using building blocks, resources discovered on the site and their own creativity.
Since launch, the game has reached 100M registered users, of which about 60M use a paid version.
Like Second Life, much of the content that makes Minecraft unique comes from its players. However, the two worlds differ in terms of the nature of incentives those players are offered. While some have managed to charge other players to engage with their content, Minecraft’s developers actually started discouraging the practice. Instead, Minecraft’s appeal was in the robustness of its creation tools, the ability to co-create with other community members, and the recognition for building something truly amazing.

Another unique attribute of the Minecraft community was that makers took their engagement beyond the virtual world itself. According to Newzoo, Minecraft-related YouTube videos were watched 4B times in May of 2015 alone. The community even crowdsourced support for an official Minecraft LEGO set, which sold out almost immediately upon release.
While Minecraft may not have directly pushed users to create external content, it acknowledged their passion for self-expression, collaboration and even bragging rights. In doing so, the game touched off a broader movement among makers that exponentially improved the experience for everyone involved.
A Look Ahead
Since their initial adoption nearly two decades ago, virtual goods have come to represent a core part of our engagement on the web. From in-game items to full-blown currency, they have been adapted by online communities to promote an ever-expanding set of experiences. By continuing to monitor their evolution, we’ll undoubtedly gain valuable insight into the changing rulebook for building lasting digital products.
Last year, we announced our Series A investment in Amino, a network of mobile-only communities focused on passion and interest verticals. The team has done a great job executing on the first phase of the business, which was to create standalone apps for communities. The communities range from large fandoms that many of us already know such as fans of Star Wars, Anime, and Pokemon to more niche communities like fans of nail art, Furry, or Undertale. Many of these communities started to grow rapidly and becoming strong self-sustaining communities, which led to the beginning of the second phase of Amino.
In July, they launched a mobile app that allows anyone to create and manage their own community. This gives everyone the power to create and build communities around the passions or interest that they care most about and find others around the world who share those same passions. As individual communities reach meaningful scale, they get spun out of the Amino app and become their own stand-alone app in the App Store. In just the first 60 days, 150,000 new communities were created. Today they are announcing that their users have created more than 250,000 communities on the platform. In addition Amino already operates a portfolio of more than 250 stand-alone apps, with hundreds or even thousands more expected in the future, created and moderated solely by their users.
The growth over the last few months has been quite impressive, but even more impressive has been the level of engagement among the Amino community members. The average user is spending over 60 minutes per day in their community or communities of choice. In comparison the average time spent per day on Facebook, Instagram, and Facebook Messenger combined is 50 minutes per day. This amazing level of engagement, coupled with the tremendous growth got other investors also excited and today Amino is also announcing their $19M Series B raise.
I’ve been continuously excited by what Ben, Yin and the team have accomplished in the last 15 months and am even more excited by what’s to come. I’m sure you have your own passion or interest that you would like to dive into so feel free to download Amino and find your community and if it doesn’t exist create it!

Last September, we were excited to announce our investment in Amino, a network of mobile-only communities focused on passion verticals. The company has made some great progress since then and today is announcing a new Series B fundraising and revealing updated metrics.
Amino’s belief, led by founders Ben Anderson and Yin Wang, is that every passion vertical deserves a dedicated and vibrant mobile community. They started by releasing stand-alone apps for many teen-specific topics, like anime, cartoons, and Minecraft. Those individual communities took off and quickly became healthy communities.
This summer, they launched a mobile app that allows anyone to create their own community. In just the first 60 days, 150,000 new communities were created. Today they are announcing that their users have created more than 250,000 communities on the platform, from Walking Dead and Vegan to Marilyn Manson and Five Nights at Freddy’s.
As each of these new communities reaches a particular scale, they get spun out of the Amino app and become their own stand-alone app in the App Store. Already, Amino operates a portfolio of more than 250 stand-alone apps, with hundreds or even thousands more expected in the future, created and moderated by their users.
As you would expect to see with vibrant communities, the engagement and usage time is very high — individual users join an average of six communities and spend an average of 60 minutes per day on the platform. As a comparison, users spend around 85 minutes per day on Reddit, an average of 50 minutes per day on Facebook, Instagram and Messenger combined, about 30 minutes per day on Snapchat and somewhere between 14 and 30 minutes per day on Tumblr.

Today, Amino is announcing a $19 million Series B fundraise led by our friends at GV (M.G. Siegler). We are welcoming Goodwater Capital (Chi-Hua Chien) and Time Warner Investments (Allison Goldberg) as new investors, and of course USV and Venrock were thrilled to participate in the round again.
We are all thrilled with Ben, Yin and the team’s substantial progress and are excited to help them realize their dream of tens of thousands of mobile communities — one for every interest and passion you can think of.
Before David Pakman joined Venrock’s New York office in 2008, he spent 12 years as an Internet entrepreneur heading up eMusic and Apple Music Group. Having been a founder himself, David became a venture capitalist to partner with entrepreneurs and help them achieve their dreams of world domination.
We asked David a couple of questions to get to know him better.
Q: Music has always been a big part of your life. When are you going on tour? Ok, seriously though. What role does music play in your life today?
Music has been the pulse of my life. It has been ever-present since I was a kid. I listen every day, think about song structure, and dream of being an actual songwriter. I bang on my drums to get rid of life’s tensions and I DJ from time to time to see if I can make people dance and feel the intensity I feel. Lately, I am starting to see some of this present in my kids, and it is fascinating to see music affecting them in somewhat similar ways. For me, music expresses the complexities of emotions in ways words cannot.
Q: What led you to venture capital?
From my earliest days of working in the Valley, many of my mentors followed the path of big company -> startups -> VC. That path became somewhat burned into my career trajectory, so I followed it. I am glad I did, because I love it. I love working with entrepreneurs more talented than I was, and helping them avoid the many pitfalls I saw up close. I also like helping them get as close as possible to their dreams of grand success.
Q: You see hundreds of business plans and pitches every year. What makes an entrepreneur or idea stand out?
Supreme ambition. One cannot be successful without it. Everything big starts with big ambition, and it’s exciting to find founders who are dreaming big.
Q: What industries are ripe for disruption?
Every industry is vulnerable at this point in the tech cycle, but in particular, industries who don’t have direct relationships with their customers and in for a doozy. They lack the data and customer knowledge to feed into machine learning systems which produce insights and product features not possible before.
Q: What keeps you up at night?
The fear of never finding another great deal.
Q: In other interviews, you’ve talked about using Twitter as a way to join in conversations with tech leaders. Aside from you, whom should we be following?
Ahh there are so many great folks on Twitter! Let’s see… I think Maya Kosoff (@mekosoff) at VanityFair is brilliantly sarcastic and also in touch with millennial consumer activity. I follow Matt Blaze (@mattblaze) from Penn to learn the truth about InfoSec, Jean-Louis Gassée (@gassee) my old colleague from Apple to help me understand the big tech companies’ moves, @YouNow to learn who the best new livestreamers to are, and @savedyouaclick and @mikeisaac because they crack me up.

Having stayed in my fair share of Airbnb’s over the years, I can vouch for the value of the human element. At one apartment in Palo Alto, my host handed me a personalized guidebook of local restaurants, annotated with suggestions from recent visitors. At another in London, my hostess proudly showed off her most prized possession — a map of the world covered in pins representing the home-towns of prior guests. In each case, these gestures made me feel like part of a community, and reduced any awkwardness I might have felt from staying in a stranger’s home. They also influenced my decision to leave highly positive reviews.
More than just a clever marketing tactic, building a feeling of community is a vital step towards enabling the sharing economy. Although it’s easy to get swept up in the economic narrative of unlocking value from our existing resources (homes, cars, savings, etc.), it’s equally important to focus on the human element that allows it to scale — trust.
The transportation market is a great example of this. Cars remain one of the most underutilized assets we own — operating at about 5% of existing capacity. Just think of the benefits we could unlock by pooling them into a shared network: transforming parking lots into public parks, reducing emissions, cutting the cost of mobility, and the list goes on! But before any of these gains can be realized, consumers have to trust autonomous vehicles enough to use them.
For those of us immersed in technology trends, trusting in automation comes more naturally than it does to the general public. According to a recent survey from AAA and the University of Michigan, three out of four drivers said they would be afraid to ride in a self-driving car. Over 80% of people surveyed said they trusted their own driving skills more than autonomous technology. And these concerns have likely grown in the wake of Tesla’s first fatal autopilot crash.
While the Federal government has made some strides towards establishing clearer safety guidelines, this still only addresses part of the problem. Having a high average rating on on Airbnb doesn’t just signal an apartment’s safety, but also its quality and reliability — two critical components in scaling trust across a large base of users.
This is an issue that Uber has been wrestling with over the last several years. While much has been written about the company’s investment in AV’s from the perspective of cost savings, the technology would also address much more immediate issues in its customer experience. For example, the most common user complaint by far stems from drivers taking bad routes in reaching a given destination.
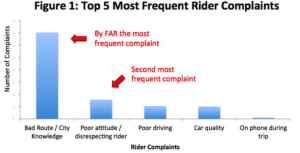
With the exception of car quality, autonomous vehicles can eliminate four out of the top five experience issues faced by customers. However, the technology alone isn’t a magic bullet. Eliminating the driver doesn’t eliminate the need for a rating system that communicates these improvements via a community of peers. If Uber can get both of these right, it would go a long way towards building trust with an even larger base of new and repeat users.
While transportation may be one of the most talked-about markets poised for disruption via the sharing economy, it certainly won’t be the last. The next decade will undoubtedly see an acceleration of collaborative consumption models into new verticals and across more participants. Along the way it’s important for founders to remember that success depends as much on figuring out empathy as it does efficiency.
Building Companies that Shape the Future
Table of contents
Introduction
PAML is a package of programs for phylogenetic analyses of DNA or protein sequences using maximum likelihood. It is maintained by Ziheng Yang and distributed under the GNU GPL v3. ANSI C source codes are distributed for UNIX/Linux/Mac OSX, and executables are provided for MS Windows. PAML is not good for tree making. It may be used to estimate parameters and test hypotheses to study the evolutionary process, when you have reconstructed trees using other programs such as PAUP*, PHYLIP, MOLPHY, PhyML, RaxML, etc.
This document is about downloading and compiling PAML and getting started. See the manual (pamlDOC.pdf) for more information about running programs in the package.
Downloading and Setting up PAML
PAML-X: A GUI for PAML
A graphical user interface, called PAML-X, has been written by Bo Xu of Institute of Zoology, Chinese Academy of Sciences in Beijing. This is written in Qt and should run on Windows, Mac OSX, and linux, although the versions for OSX and linux may not be well tested. You download PAML, and also PAML-X. When you run PAML-X for the first time, you specify the PAML folder name. The links for downloading are listed below.
Use of pamlX1.3.1 requires paml4.9 or later.
The following is written for the naive user. If you know things like folders, executable files, and search path, there is no need for you to follow the instructions here.
PAML for Windows 9x/NT/2000/XP/Vista/7
Download and save the archive paml4.9j.tgz on your local disk. (Make sure that you save the file using the correct file name. If Internet Explorer changes the file extension to .gz, you should change it back to .tgz before double-clicking). Unpack the archive into a folder, using Winzip, say. Remember the name of the folder. The Windows executables are in paml4.9j/bin/. I suggest that you create a folder for local prorams and move the PAML executables there. Here are some notes for doing that.
Setting up a folder of local programs and changing the search path. You need to do this for your user account only once. Suppose your user folder is C:\Users\Ziheng. [Please replace this with your own user folder in the following examples.] This is the default user folder for me on Vista or Windows 7. On Windows XP, it is more unwieldly, somthing like C:\Documents and Settings\Ziheng. Use Windows Explorer to create a folder called bin inside your user folder, that is, C:\Users\Ziheng\bin. Or if you are the boss of your PC, you may prefer the folder C:\bin. Anyway, this is the folder for holding executable programs.Next we will add this folder onto the search path, which the OS uses to search for executable programs. The following is for Windows Vista. The menu may be slightly different on Win 2000/XP, but you should have no problem finding your way. Open Control Panel. Choose Classic View. Double-click on System. Choose Advanced System Settings, and click on the tab Advanced. Click on the button Environment Variables. Under User variables, double-click on the variable Path to edit. Click on the "variable value" field and move the cursor to the beginning. Insert the name of our program folder C:\Users\Ziheng\Bin; or C:\Bin; or whatever folder you have created. Note that the semicolon separates the folder names. Be careful not to introduce any errors. Click on OK.
Copy the PAML executables. Copy or move the pre-compiled executables (baseml.exe, codeml.exe, evolver.exe, chi2.exe, etc.) from the paml4.9j\bin\ folder to the local programs folder C:\Users\Ziheng\Bin\. After this, you can execute any of these programs from a command prompt whever you are. If you like, you can rename baseml.exe and codeml.exe as baseml4.exe and codeml4.exe respectively, to include the version number. (You will then run the program by the command codeml4 instead of codeml.)
You can also copy other command-line programs you downloaded into this folder, such as mb, RAxML, PhyML programs.
Running a PAML program. Avoid double-clicking the program names from Windows Explorer. That way you won't see any error messages on the screen when the program crashes. Instead start a "command prompt" box. For example, Start - Programs - Accessories - Command Prompt). Or Start - Run - type cmd and OK. You can right-click on the title bar and choose Properties to change the size, font, colour of the window. cd to the folder which contains your user files, and type the command name. Here we cd to the paml folder (suppose you have extracted the archive into C:\Programs\paml4.9j\) and run program using the default files.
Because there is no executable file called codeml.exe (or codeml.bat, etc.) in your current folder, the OS will look for it in the folders listed in the environment variable path. It will find and execute codeml.exe in the C:\Users\Ziheng\Bin folder. You can also specify the full path of the exectuable program, with something like the following:
Some codeml analyses use an amino acid distance (e.g., grantham.dat) or substitution rate matrice (e.g., wag.dat). You will then need to copy the necessary file to your current folder. Otherwise the program will ask you to input the full path-name for the file.
UNIX/Linux and Mac OSX
For the MAC, we have compiled a version for MAC OSX: paml4.8a.macosx.tgz. You open a command terminal by Applications-Utilities-Terminal.UNIX, linux, and other systems. Download the the Win32 archive and save and unpack it into a local folder. Remove the Windows executables (.exe files) in the bin/ folder. (Replace 4.9j with the appropriate version number in the following commands.)
Then cd to the paml folder (you have to remember where you saved the files) and again cd to the src/ folder and compile the programs. Setting up a folder of local programs and change your initialization file for the shell. You need to do this for your user account only once. First check that there is a bin/ folder inside your account. If not, create one.Then modify your path to include the bin/ folder in the initialization file for the shell. You can use more /etc/passwd to see which shell you run. Below are notes for the C shell and bash shell. There are other shells, but these two are commonly used.
(1) If you see /bin/csh for your account in the /etc/passwd file, you are running the C shell, and the intialization file is .cshrc in your root folder. You can use more .cshrc to see its content if it is present. Use a text editor (such as emacs, vi, SimpleText, etc.) to edit (or create, if one does not exist) the file, by something like and insert the following lineThe different fields are separated by spaces. Here '.' means the current folder, and ~/ means your root folder, and ~/bin means the bin folder you created, and $path is whatever folders are already in the path.
(2) If you see /bin/bash in the file /etc/passwd for your account, you are running the bash shell, and the initialization file is .bashrc. Use a text editor to open .bashrc and insert the following line
This changes the environment variable PATH. The different fields are separated by colon : and not space. If the file does not exist, create one.After you have changed and saved the initialization file, every time you start a new shell, the path is automatically set for you. You can then cd to the folder which contain your data files and run paml programs there. The following moves to the paml folder (suppose you have extracted the archive into Programs/paml4.9j/ on your account) and run program using the default files.
As the path is set up properly, this is equivalent to
Note that Windows uses \ while Unix uses /, and Windows is case-insensitive while Unix is case-sensitive.
MAC OSX. If you have a G5 or if you would like to compile the programs yourself, please follow the notes here. I understand that the Apple XCODE is now automatically installed on your mac. Otherwise you will have to download and install the mac XCODE system, which includes the C compiler. Without a C compiler, you will get a "Command not found" error when you type gcc or cc at the command terminal.Download the Windows archive. Open a command terminal (Applications-Utilities-Terminal) and compile and run the programs from the terminal. Remove the .exe files in the bin/ folder.
More specifically, open up the file Makefile in the src/ folder. Add # at the beginning of the following line to comment it out. CFLAGS = -O4 -funroll-loops -fomit-frame-pointer -finline-functions
Delete the # at the beginning of the line for either G5 or intel, depending on your machine, to uncomment the line.
#MAC OSX G5:
#CFLAGS = -mcpu=G5 -O4 -funroll-loops -fomit-frame-pointer -finline-functions
#MAC OSX intel:
#CFLAGS = -march=pentium-m -O4 -funroll-loops -fomit-frame-pointer -finline-functions
Save the file. At the command line, type make and hit Enter. After the programs are successfully compiled, delete the .o files and move the executables to the bin/ folder.
rm *.o
mv baseml basemlg codeml pamp evolver yn00 chi2 ../bin
You may want to mv the executables into the bin/ folder on your accounts rather than the paml main folder. And finally, if your current folder is not on your search path, you will have to add ./ in front of the executable file name; that is, use ./codeml instead of codeml to run codeml. See the notes for unix systems above.
Some notes about running programs in PAML
A number of example datasets are included in the package. They are typically datasets analyzed in the original papers that described the methods. I suggest that you get a copy of the paper, and run the example datasets to reproduce our results first, before analyzing your own data. This should serve to identify errors in the program, help you to get familiar with the format of the data file and the interpertation of results.
Most programs in the PAML package have control files that specify the names of the sequence data file, the tree structure file, and models and options for the analysis. The default control files are for and , for , for , for . The progam does not have a control file, and uses a simple user interface. All you do is to type and then choose the options. For other programs, you should prepare a sequence data file and a tree structure file, and modify the appropriate control files before running the programs. The formats of those files are detailed in the documentation.PAML Resources on the web
Questions and Bug Reports
(a) If you discover a bug, please post an item at the discussion group or send me a message. I will try to visit the discussion group every week or every two weeks. When describing the problem, please mention the version number, what you did and what happened. In particular copy any error message on the screen into the message. Please try to make it easy for me to duplicate the problem on my own computers.(b) If you have questions about using the programs, please try to find answers by reading the manual (doc/pamlDOC.pdf), the paml FAQ page (doc/pamlFAQ.pdf), or the postings at the Google discussion site. Use example data files included in the package to get to know the normal behavior of the programs. Often you should be able to tell from the screen output whether the program reads the sequence and tree files correctly.
If none of these is helpful, please post your question at the discussion group, for me or other users of paml to answer. The discussion group was set up to reduce the amount of time I have to spend in answering user questions. Please do not send me messages. I will most likely ignore emails asking questions about how to use the programs. I apologize for the inadequate support.
Webmaster: Ziheng Yang
Setup and Dependencies
This file describes the installation process for Amino.
The following dependies are required or optional. Please see below for the corresponding list of Debian and Ubuntu packages. Also, please consult the errata notes below as some package versions have missing features or bugs that require workarounds.
Required Dependencies
These dependecies are required to compile and use Amino:
Optional Dependencies
These dependecies are optional and may be used to enable additional features in Amino:
- Robot Models (URDF, COLLADA, Wavefront, etc.):
- GUI / Visualization:
- OpenGL
- SDL2
- plus everything under Robot Models, if you want to visualize meshes, URDF, etc.
- Raytracing (everything under Robot Models, plus):
- Motion Planning:
- FCL
- OMPL
- plus everything under Robot Models, if you want to handle meshes, URDF, etc.
- Java Bindings
- Optimization, any or all of the following:
Debian and Ubuntu GNU/Linux
Most the dependencies on Debian or Ubuntu GNU/Linux can be installed via APT. The following command should install all/most dependencies. For distribution-specific package lists, please see the files under which are used for distribution-specific integration tests.
sudo apt-get install build-essential gfortran \ autoconf automake libtool autoconf-archive autotools-dev \ maxima libblas-dev liblapack-dev \ libglew-dev libsdl2-dev \ libfcl-dev libompl-dev \ sbcl \ default-jdk \ blender flex povray ffmpeg \ coinor-libclp-dev libglpk-dev liblpsolve55-dev libnlopt-devNow proceed to Quicklisp Setup below.
Installation Errata
Some package versions are missing features or contain minor bugs that impede usage with amino. A listing of issues encountered so far is below:
OMPL Missing Eigen dependency
Version 1.4.2 of OMPL and the corresponding Debian/Ubuntu packages are missing a required dependency on libeigen. To resolve, you may need to do the following:
- Manually install libeigen: sudo apt-get install libeigen3-dev
- Manually add the eigen include directory to the ompl pkg-config file. The ompl pkg-config file will typically be in . The eigen include path will typically be . Thus, you may change the Cflags entry in to: Cflags: -I${includedir} -I/usr/include/eigen3
Blender Missing COLLADA Support
Some versions of Blender in Ubuntu and Debian do not support the COLLADA format for 3D meshes, so you may need to install Blender manually in this case (see https://www.blender.org/download/).
SBCL and CFFI incompatibility
The versions of SBCL in some distributions (e.g., SBCL 1.2.4 in Debian Jessie) do not work with new versions of CFFI. In these cases, you will need to install SBCL manually (see http://www.sbcl.org/platform-table.html).
Mac OS X
Install Dependencies via Homebrew
If you use the Homebrew package manager, you can install the dependencies as follows:
- Install packages: brew tap homebrew/science brew install autoconf-archive openblas maxima sdl2 libtool ompl brew install https://raw.github.com/dartsim/homebrew-dart/master/fcl.rb
- Set the CPPFLAGS variable so that the header can be found: CPPFLAGS=-I/usr/local/opt/openblas/include
- Proceed to Blender Setup below
Install Dependencies via MacPorts
If you use the MacPorts package manager, you can install the dependencies as follows:
- Install packages: sudo port install \ coreutils wget \ autoconf-archive maxima f2c flex sbcl \ OpenBLAS \ libsdl2 povray ffmpeg \ fcl ompl \ glpk
Ensure that or contains the MacPorts lib directory (typically ).
echo $LD_LIBRARY_PATH echo $DYLD_LIBRARY_PATHIf does not appear in either or , do the following (and consider adding it to your shell startup script).
export LD_LIBRARY_PATH="/opt/local/lib:$LD_LIBRARY_PATH"Ensure that autoconf can find the MacPorts-installed header and library files by editing the file under your preferred installation prefix (default: )
vi /usr/local/share/config.siteEnsure that the and variables in config.site contain the MacPorts directories.
CPPFLAGS="-I/opt/local/include" LDFLAGS="-L/opt/local/lib"- Proceed to Blender Setup below
Blender Setup
When installing blender on Mac OS X, you may need to create a wrapper script. If you copy the blender binaries to , then then
touch /usr/local/bin/blender chmod a+x /usr/local/bin/blender vi /usr/local/bin/blenderand add the following:
#!/bin/sh exec /usr/local/blender-2/blender.app/Contents/MacOS/blender $@
Now proceed to Quicklisp Setup below.
Quicklisp Setup
Finally, install Quicklisp manually, if desired for ray tracing and robot model compilation.
wget https://beta.quicklisp.org/quicklisp.lisp sbcl --load quicklisp.lisp \ --eval '(quicklisp-quickstart:install)' \ --eval '(ql:add-to-init-file)' \ --eval '(quit)'If you have obtained amino from the git repo, you need to initialize the git submodules and autotools build scripts.
git submodule init && git submodule update && autoreconf -iThis step is not necessary when you have obtained a distribution tarball which already contains the submodule source tree and autoconf-generated configure script.
Configure for your system. To see optional features which may be enabled or disabled, run:
./configure --helpThen run configure (adding any flags you may need for your system):
./configure- Build: make
Install:
sudo make installIf you need to later uninstall amino, use the conventional command.
The Amino distribution includes a number of demo programs. Several of these demos use URDF files which must be obtained separately.
Obtain URDF Files
- If you already have an existing ROS installation, you can install the ROS package, for example on ROS Indigo: sudo apt-get install ros-indigo-baxter-description export ROS_PACKAGE_PATH=/opt/ros/indigo/share
- An existing ROS installation is not necessary, however, and you can install only the baxter URDF and meshes: cd .. git clone https://github.com/RethinkRobotics/baxter_common export ROS_PACKAGE_PATH=`pwd`/baxter_common cd amino
Build Demos
(Re)-configure to enable demos:
./configure --enable-demos --enable-demo-baxterNote: On Mac OS X, due to dynamic loading issues, it may be necessary to first build and install amino, and the re-configure and re-build amino with the demos enabled. Under GNU/Linux, it is generally possible to enable the demos during the initial build and without installing Amino beforehand.
- Build: make
Run Demos
Many demo programs may be built. The following comand will list the built demos:
find ./demo -type f -executable \ -not -name '*.so' \ -not -path '*.libs*'The demo will lauch the Viewer GUI with a simple scene compiled from a scene file.
./demo/simple-rx/simple-scenefileSeveral demos using the Baxter model show various features. Each can be invoked without arguments.
- displays the baxter via dynamic loading
- via static linking
- moves the baxter arm in workspace
- performs collision checking
- computes an inverse kinematics solution
- computes a motion plan
- computes a motion plan to a workspace goal
- computes a sequence of motion plans
Basic Tests
- To run the unit tests: make check
- To create and check the distribution tarball: make distcheck
Docker Tests
Several Docker files are included in which enable building testing amino in a container with a clean OS installation. These Dockerfiles are also used in the Continuous Integration tests.
- To build a docker image using the file: ./script/docker-build.sh ubuntu-xenial
- To build amino and run tests using docker image built from file: ./script/docker-check.sh ubuntu-xenial
- fails with when checking for cffi-grovel.
- Older versions of SBCL (around 1.2.4) have issues with current versions of CFFI. Please try installing a recent SBCL (>1.3.4).
- I get error messages about missing .obj files or Blender being unable to convert a .dae to Wavefront OBJ.
- A: We use Blender to convert various mesh formats to Wavefront OBJ, then import the OBJ file. The Blender binaries in the Debian and Ubuntu repositories (as of Jessie and Trusty) are not built with COLLADA (.dae) support. You can download the prebuilt binaries from http://www.blender.org/ which do support COLLADA.
- When I try to compile a URDF file, I receive the error "aarx.core: not found".
- A: URDF support in amino is only built if the necessary dependencies are installed. Please ensure that you have SBCL, Quicklisp, and Sycamore installed and rebuild amino if necessary.
- When building , I get an enormous stack trace, starting with: Unable to load any of the alternatives: ("libamino_planning.so" (:DEFAULT "libamino_planning"))
This means that SBCL is unable to load the planning library or one of its dependecies, such as OMPL. Typically, this means your linker is not configured properly.
Sometimes, you just need to run or to update the linker cache.
If doesn't work, you can set the variable. First, find the location of libompl.so, e.g., by calling . Then, add the directory to your . Most commonly, this will mean adding one of the following lines to your shell startup files (e.g., .bashrc):
export LD_LIBRARY_PATH="/usr/local/lib/:$LD_LIBRARY_PATH" export LD_LIBRARY_PATH="/usr/local/lib/x86_64-linux-gnu/:$LD_LIBRARY_PATH"
- When building , I get an enormous stack trace, starting with something like: Unable to load foreign library (LIBAMINO-PLANNING). Error opening shared object "libamino-planning.so": /home/user/workspace/amino/.libs/libamino-planning.so: undefined symbol: _ZNK4ompl4base20RealVectorStateSpace10getMeasureEv.
- This error may occur when you have multiple incompatible versions of OMPL installed and the compiler finds one version while the runtime linker finds a different version. Either modify your header () and linking () paths, or remove the additional versions of OMPL.
Copyright (C) 1994, 1995, 1996, 1999, 2000, 2001, 2002, 2004, 2005, 2006, 2007, 2008, 2009 Free Software Foundation, Inc.
Copying and distribution of this file, with or without modification, are permitted in any medium without royalty provided the copyright notice and this notice are preserved. This file is offered as-is, without warranty of any kind.
Briefly, the shell commands should configure, build, and install this package. The following more-detailed instructions are generic; see the file for instructions specific to this package. Some packages provide this file but do not implement all of the features documented below. The lack of an optional feature in a given package is not necessarily a bug. More recommendations for GNU packages can be found in *note Makefile Conventions: (standards)Makefile Conventions.
The shell script attempts to guess correct values for various system-dependent variables used during compilation. It uses those values to create a in each directory of the package. It may also create one or more files containing system-dependent definitions. Finally, it creates a shell script that you can run in the future to recreate the current configuration, and a file containing compiler output (useful mainly for debugging ).
It can also use an optional file (typically called and enabled with or simply ) that saves the results of its tests to speed up reconfiguring. Caching is disabled by default to prevent problems with accidental use of stale cache files.
If you need to do unusual things to compile the package, please try to figure out how could check whether to do them, and mail diffs or instructions to the address given in the so they can be considered for the next release. If you are using the cache, and at some point contains results you don't want to keep, you may remove or edit it.
The file (or ) is used to create by a program called . You need if you want to change it or regenerate using a newer version of .
The simplest way to compile this package is:
to the directory containing the package's source code and type to configure the package for your system.
Running might take a while. While running, it prints some messages telling which features it is checking for.
- Type to compile the package.
- Optionally, type to run any self-tests that come with the package, generally using the just-built uninstalled binaries.
- Type to install the programs and any data files and documentation. When installing into a prefix owned by root, it is recommended that the package be configured and built as a regular user, and only the phase executed with root privileges.
- Optionally, type to repeat any self-tests, but this time using the binaries in their final installed location. This target does not install anything. Running this target as a regular user, particularly if the prior required root privileges, verifies that the installation completed correctly.
- You can remove the program binaries and object files from the source code directory by typing . To also remove the files that created (so you can compile the package for a different kind of computer), type . There is also a target, but that is intended mainly for the package's developers. If you use it, you may have to get all sorts of other programs in order to regenerate files that came with the distribution.
- Often, you can also type to remove the installed files again. In practice, not all packages have tested that uninstallation works correctly, even though it is required by the GNU Coding Standards.
- Some packages, particularly those that use Automake, provide , which can by used by developers to test that all other targets like and work correctly. This target is generally not run by end users.
Some systems require unusual options for compilation or linking that the script does not know about. Run for details on some of the pertinent environment variables.
You can give initial values for configuration parameters by setting variables in the command line or in the environment. Here is an example:
./configure CC=c99 CFLAGS=-g LIBS=-lposix*Note Defining Variables::, for more details.
You can compile the package for more than one kind of computer at the same time, by placing the object files for each architecture in their own directory. To do this, you can use GNU . to the directory where you want the object files and executables to go and run the script. automatically checks for the source code in the directory that is in and in . This is known as a "VPATH" build.
With a non-GNU , it is safer to compile the package for one architecture at a time in the source code directory. After you have installed the package for one architecture, use before reconfiguring for another architecture.
On MacOS X 10.5 and later systems, you can create libraries and executables that work on multiple system types–known as "fat" or "universal" binaries–by specifying multiple options to the compiler but only a single option to the preprocessor. Like this:
./configure CC="gcc -arch i386 -arch x86_64 -arch ppc -arch ppc64" \ CXX="g++ -arch i386 -arch x86_64 -arch ppc -arch ppc64" \ CPP="gcc -E" CXXCPP="g++ -E"This is not guaranteed to produce working output in all cases, you may have to build one architecture at a time and combine the results using the tool if you have problems.
By default, installs the package's commands under , include files under , etc. You can specify an installation prefix other than by giving the option , where PREFIX must be an absolute file name.
You can specify separate installation prefixes for architecture-specific files and architecture-independent files. If you pass the option to , the package uses PREFIX as the prefix for installing programs and libraries. Documentation and other data files still use the regular prefix.
In addition, if you use an unusual directory layout you can give options like to specify different values for particular kinds of files. Run for a list of the directories you can set and what kinds of files go in them. In general, the default for these options is expressed in terms of , so that specifying just will affect all of the other directory specifications that were not explicitly provided.
The most portable way to affect installation locations is to pass the correct locations to ; however, many packages provide one or both of the following shortcuts of passing variable assignments to the command line to change installation locations without having to reconfigure or recompile.
The first method involves providing an override variable for each affected directory. For example, will choose an alternate location for all directory configuration variables that were expressed in terms of . Any directories that were specified during , but not in terms of , must each be overridden at install time for the entire installation to be relocated. The approach of makefile variable overrides for each directory variable is required by the GNU Coding Standards, and ideally causes no recompilation. However, some platforms have known limitations with the semantics of shared libraries that end up requiring recompilation when using this method, particularly noticeable in packages that use GNU Libtool.
The second method involves providing the variable. For example, will prepend before all installation names. The approach of overrides is not required by the GNU Coding Standards, and does not work on platforms that have drive letters. On the other hand, it does better at avoiding recompilation issues, and works well even when some directory options were not specified in terms of at time.
If the package supports it, you can cause programs to be installed with an extra prefix or suffix on their names by giving the option or .
Some packages pay attention to options to , where FEATURE indicates an optional part of the package. They may also pay attention to options, where PACKAGE is something like or (for the X Window System). The should mention any and options that the package recognizes.
For packages that use the X Window System, can usually find the X include and library files automatically, but if it doesn't, you can use the options and to specify their locations.
Some packages offer the ability to configure how verbose the execution of will be. For these packages, running sets the default to minimal output, which can be overridden with ; while running sets the default to verbose, which can be overridden with .
On HP-UX, the default C compiler is not ANSI C compatible. If GNU CC is not installed, it is recommended to use the following options in order to use an ANSI C compiler:
./configure CC="cc -Ae -D_XOPEN_SOURCE=500"and if that doesn't work, install pre-built binaries of GCC for HP-UX.
On OSF/1 a.k.a. Tru64, some versions of the default C compiler cannot parse its header file. The option can be used as a workaround. If GNU CC is not installed, it is therefore recommended to try
./configure CC="cc"and if that doesn't work, try
./configure CC="cc -nodtk"On Solaris, don't put early in your . This directory contains several dysfunctional programs; working variants of these programs are available in . So, if you need in your , put it after.
On Haiku, software installed for all users goes in , not . It is recommended to use the following options:
./configure --prefix=/boot/commonThere may be some features cannot figure out automatically, but needs to determine by the type of machine the package will run on. Usually, assuming the package is built to be run on the same architectures, can figure that out, but if it prints a message saying it cannot guess the machine type, give it the option. TYPE can either be a short name for the system type, such as , or a canonical name which has the form:
CPU-COMPANY-SYSTEMwhere SYSTEM can have one of these forms:
OS KERNEL-OSSee the file for the possible values of each field. If isn't included in this package, then this package doesn't need to know the machine type.
If you are building compiler tools for cross-compiling, you should use the option to select the type of system they will produce code for.
If you want to use a cross compiler, that generates code for a platform different from the build platform, you should specify the "host" platform (i.e., that on which the generated programs will eventually be run) with .
If you want to set default values for scripts to share, you can create a site shell script called that gives default values for variables like , , and . looks for if it exists, then if it exists. Or, you can set the environment variable to the location of the site script. A warning: not all scripts look for a site script.
Variables not defined in a site shell script can be set in the environment passed to . However, some packages may run configure again during the build, and the customized values of these variables may be lost. In order to avoid this problem, you should set them in the command line, using . For example:
./configure CC=/usr/local2/bin/gcccauses the specified to be used as the C compiler (unless it is overridden in the site shell script).
Unfortunately, this technique does not work for due to an Autoconf bug. Until the bug is fixed you can use this workaround:
CONFIG_SHELL=/bin/bash /bin/bash ./configure CONFIG_SHELL=/bin/bashrecognizes the following options to control how it operates.
--help -h Print a summary of all of the options to `configure`, and exit. --help=short --help=recursive Print a summary of the options unique to this package's `configure`, and exit. The `short` variant lists options used only in the top level, while the `recursive` variant lists options also present in any nested packages. --version -V Print the version of Autoconf used to generate the `configure` script, and exit. --cache-file=FILE Enable the cache: use and save the results of the tests in FILE, traditionally `config.cache`. FILE defaults to `/dev/null` to disable caching. --config-cache -C Alias for `--cache-file=config.cache`. --quiet --silent -q Do not print messages saying which checks are being made. To suppress all normal output, redirect it to `/dev/null` (any error messages will still be shown). --srcdir=DIR Look for the package's source code in directory DIR. Usually `configure` can determine that directory automatically. --prefix=DIR Use DIR as the installation prefix. *note Installation Names:: for more details, including other options available for fine-tuning the installation locations. --no-create -n Run the configure checks, but stop before creating any output files. `configure` also accepts some other, not widely useful, options. Run `configure --help` for more details.What’s New in the Amino App Pc Download Archives?
Screen Shot
System Requirements for Amino App Pc Download Archives
- First, download the Amino App Pc Download Archives
-
You can download its setup from given links:

Amino App Pc Download Archives & Free Download

Amino App Pc Download Archives& Apps for Laptop & PC Free Download
